

Hey all, so in this article I am going to take a look at the new Ingestion Client for Azure Speech that was recently Introduced by the Azure Cognitive Services team at Microsoft.
This new announcement enables developers to ingest audio files and get them transcribed by the Azure Speech Infrastructure. This article will take a look at the Azure Resource Manager (ARM) Template that has been created to stand up the required Azure resources to enable the capability of storing an Audio file in an Azure Storage Account and have that event trigger the Batch Ingestion Client to do some transcription and save the results back to the storage account as well as sending any logging events for storage for onward processing.
The Architecture
This diagram shows the architecture that the ARM template defined will create, We have two modes of operation: Batch Mode or Real Time Mode which we will talk a little about later in this article.

Prerequisites
We will require an Azure Account/Subscription as well as an Azure Speech Services Key so lets head on over to our Azure Portal:


Search for Speech and Click Create
Give it a name and select the Subscription, Location, Pricing Tier and Resource Group
Click Create

Once complete, we can Go to resource
We can find our Key and also a reminder of the location we selected (in our example UK South).
We will also need to download and install the Azure Storage Explorer to follow along with this demo.
Select the Operating Mode
Next we have to choose between two operating modes noting that the Audio files can be processed by the Speech to Text API v3.0 for any batch processing, or the Speech SDK for real-time processing.
Batch Mode
In batch mode, audio files are processed in batches. The Azure Function creates a transcription request periodically with all the files that have been requested up to that point. If the number of files is large then many requests will be raised. Consider the following about batch mode:
- Low Azure Function costs. Two Azure Functions coordinate the process and run for milliseconds.
- Diarization and Sentiment. Offered in Batch Mode only.
- Higher Latency. Transcripts are scheduled and executed based on capacity of cluster. Real time mode takes priority.
- Multiple Audio Formats are supported.
- You will need to deploy the Batch ARM Template from the repository for this operating mode.
Real Time Mode
In real time mode, audio files are downloaded and streamed from the Azure Function to the real time Azure Speech endpoint. Consider the following about real time mode:
Higher Azure Function costs. A single type Azure Functions will handle the process for each file and run at least for half the audio length.
2x processing of audio files. For example, a 10-min file is transcribed in 5mins.
Only .wav PCM is supported.
You will need to use the Real Time ARM Template from the repository for this operating mode.
- Higher Azure Function costs. A single type Azure Functions will handle the process for each file and run at least for half the audio length.
- 2x processing of audio files. For example, a 10-min file is transcribed in 5mins.
- Only .wav PCM is supported.
- You will need to use the Real Time ARM Template from the repository for this operating mode.
Setting up the Ingestion Client
So for the purposes of this example I have chosen to use the Batch Processing Model, in reality the models are very similar with the main differences being that there is no diarization and sentiment options with Real Time mode, nor the ability for any post processing with SQL.
If we go back to the portal and Create a new resource, this time we will search for Template Deployment:


Click Build your own template in the editor
Next we can download or copy the Batch ARM Template

Click Load File or copy the JSON Text into the editor

Click Save (we can edit this after in the Deployment)
We will now be presented with a list of items to select or fill in as follows:

Select our Subscription and Resource Group

- We will need to enter a name for our storage account and this will be created for us
- Our locale relates to the language and region we wish to translate to
- Enter our Speech Services Key
- From here we can select a number of configurations around profanity filtering, punctuation, diarization (Speaker Separation), see my selections above, purely used to demo.
- Finally we have the option to add a SQL User and Password, leaving this blank will remove the creation of the SQL DB.

Click Review + Create
Click Create – this should only take a few minutes to create all the resources as per the architecture diagram above
Once complete we should end up with the following in our Azure Resource Group:

Lets Run a Test for the first time
Using Azure Storage Explorer upload an audio file, note that the following file extensions are acceptable for Batch processing:

We can see the following folder structure has been configured within our storage account:

I am going to save an audio file into the audio-input container:

So for the first few attempts I was getting errors saying that ‘The Recordings URI contains invalid data.’ So after a quick search of the internet I spotted a few others with this problem. For the purposes of this demo, i redeployed the template but removed the options for sentiment and diarization etc. just to see if it was something to do with that. After redeploying I can see my Azure Function running on its 2 minute timer:

Then I can see the FetchTranscript Function running:
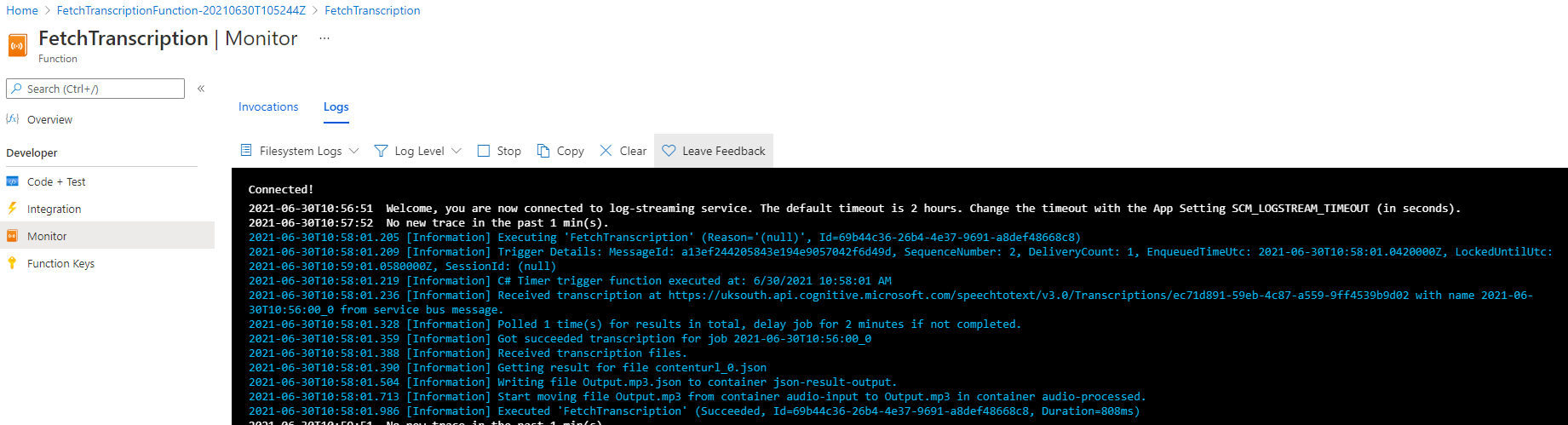
Which as you can see simply writes the output as JSON in the json-result-output folder in my storage account:

Lets look at the results
If we now open up the JSON file we can see the transcription results:

Ive not included the full file here, but you can see the output in JSON format that can then be utilised for further processing or inclusion within whatever system you are looking to develop.

Here you can see it almost got my surname right! But you can see the confidence rating as well as a few other properties that can be utilised.
I hope you have found this post interesting! Good luck with utilising the Azure Speech Services on a project soon! Just to add, its great the the team have developed this style of ingestion client which ties up a number of different azure components to offer a solution to complete batch or real time transcription!
